On GPUs, ranges, latency, and superoptimisers
Not long ago, I put together a small library that provides an interface similar to the range-v3 library and uses CUDA to execute all operations on GPUs. I’ve implemented the basics: map, filter, reduce operations, just enough to serve as a proof of concept. In essence, it is quite similar to Thrust; just the interface is different, based on ranges instead of iterators. As one would expect, the initial implementation wasn’t heavily optimised, but the time has come to improve the performance. This was an excellent opportunity to look more closely at the architecture of modern GPUs – Turing in this case.
Firstly, let’s have a look at a rather straightforward pipeline that sums integers in an array that already exists in the GPU memory.
ranges_gpu::buffer_pool pool{4};
void sum_i32_array(benchmark::State& s) {
auto array = ranges_gpu::view::iota(0, int(s.range(0)))
| ranges_gpu::action::to_gpu();
for (auto _ : s) {
auto value = array
| ranges_gpu::action::reduce(0,
[] __device__(auto a, auto b) { return a + b; },
ranges_gpu::pool_allocator<int>(pool));
benchmark::DoNotOptimize(value);
}
}
It is worth noting that this code is taking advantage of a buffer_pool and a pool_allocator. The reduce operation needs to allocate a temporary buffer to store intermediate results. cudaMalloc can be quite expensive, and for large buffers, I saw it dominate the cost of reducing the array. buffer_pool keeps around the specified number of buffers so that subsequent operations can reuse them without additional cudaMalloc and cudaFree calls. It is a quite simplistic solution, and can easily lead to out of memory if one is not careful, but is good enough for our purposes.
In general, a range consumed by action::reduce can either be of a known or unknown size. The latter happens, for example, if the pipeline contains a filtering stage view::filter, and essentially forces the reduce to work with an equivalent of std::optional<T> instead of T. It is not a significant complication, but for the sake of simplicity, we will look at the case where the size of the range is known at the kernel launch.
template<typename V, typename T, typename F>
__global__ void do_reduce(size_t total_size, V in, T init, F fn, T* out) {
auto id = blockIdx.x * blockDim.x + threadIdx.x;
if (id < total_size) { out[id] = in[id]; }
auto tid = threadIdx.x;
auto stride = blockDim.x / 2;
while (stride) {
__syncthreads();
if (tid < stride && id + stride < total_size) {
out[id] = fn(out[id], out[id + stride]);
}
stride /= 2;
}
if (id == 0) { out[0] = fn(out[0], init); }
}
template<typename T, typename F>
__global__ void do_reduce_blocks(size_t total_size, size_t step, F fn, T* out) {
auto id = blockIdx.x * blockDim.x + threadIdx.x;
auto tid = threadIdx.x;
auto stride = blockDim.x / 2;
while (stride) {
__syncthreads();
if (tid < stride && (id + stride) * step < total_size) {
out[id * step] = fn(out[id * step], out[(id + stride) * step]);
}
stride /= 2;
}
}
Our starting point is a somewhat naive implementation of reduce that uses two different kernels and a lot of global memory accesses. First, we launch do_reduce with as many threads as there are elements in the input range in. The kernel evaluates each element, and then each thread block reduces elements owned by its threads. For an input range of size n at the end of this kernel, we end up with ceil(n / blockDim.x) elements. Then, do_reduce_blocks kernel is launched as many times as necessary, each time reducing a block worth of values.
The algorithm reduces a range a thread block is responsible for in a logarithmic number of steps. At each step, there is a stride of active threads (starting with stride = blockDim.x / 2) and each thread applying the binary operation fn to elements at positions threadIdx.x and threadIdx.x + stride. stride in each step is half of the stride of the previous step. Steps are separated by __syncthreads() to synchronise all threads in a block properly. At any time the threads in a block can be partitioned into two groups: those with the index less than the current stride which still are doing useful work and the rest. This arrangement minimises the thread divergence inside warps.
It is time to check what code nvcc generates for Turing GPU architecture. The main reduce loop in do_reduce looks as follows.
0x00000110 --:-:-:Y:1 IMAD.IADD R5, R0, 0x1, R7
0x00000120 --:-:-:Y:5 BAR.SYNC 0x0
0x00000130 --:-:-:Y:1 ISETP.GE.U32.AND P0, PT, R5, c[0x0][0x160], PT
0x00000140 --:-:-:Y:3 BSSY B0, 0x210
0x00000150 --:-:-:-:4 ISETP.GE.U32.AND.EX P0, PT, RZ, c[0x0][0x164], PT, P0
0x00000160 --:-:-:Y:2 ISETP.GE.U32.OR P0, PT, R8, R7, P0
0x00000170 --:-:-:-:4 SHF.R.U32.HI R7, RZ, 0x1, R7
0x00000180 --:-:-:-:6 ISETP.NE.AND P1, PT, R7, RZ, PT
0x00000190 01:-:-:Y:6 @P0 BRA 0x200
0x000001a0 --:-:-:Y:1 LEA R4, P0, R5, c[0x0][0x180], 0x2
0x000001b0 --:-:2:Y:3 LDG.E.SYS R6, [R2]
0x000001c0 --:-:-:-:8 LEA.HI.X R5, R5, c[0x0][0x184], RZ, 0x2, P0
0x000001d0 --:-:2:Y:2 LDG.E.SYS R5, [R4]
0x000001e0 04:-:-:-:8 IMAD.IADD R9, R6, 0x1, R5
0x000001f0 --:0:-:Y:2 STG.E.SYS [R2], R9
0x00000200 --:-:-:Y:5 BSYNC B0
0x00000210 --:-:-:Y:5 @P1 BRA 0x110
Wmsk:Rd:Wr:Y:S before each instruction is control information. Turing, not unlike its predecessors, relies rather heavily on the compiler making the scheduling decisions and taking care of the dependencies between instructions. The meaning of the fields is as follows:
S– stall cycles. Indicates how long the scheduler should wait before issuing the next instruction.Y– yield hints. Tells the scheduler whether it should prefer issuing the next instruction from the current or different warpWr– write barrier index. For variable-latency instructions stall cycles field is not sufficient to handle data hazards. This field allows specifying the index of one of the six barriers that the consumer of the data produced by this instruction can wait on.Rd– read barrier index. Some instructions are susceptible to write-after-read hazards. Similarly, to the write barrier index, read barrier index can be used to make the instructions that would overwrite the source register of a previous instruction wait until it is safe to do so.Wmsk– wait barrier mask. A bitmask indicating which barriers this instruction needs to wait for.
When it comes to registers Turing ISA offers us:
- 255 32-bit general-purpose registers (
Rn) plus zero registerRZ. - 63 32-bit uniform general-purpose registers (
URn) plus zero uniform registerURZ. - 7 1-bit predicate registers (
Pn) plus true predicate registerPT.
Each instruction can be predicated. Operands can be registers, immediate values, global or shared memory locations, constant memory locations (c[x][y]), etc. 64-bit values are usually handled by emitting two special variants of the instruction that operate on the lower and higher 32-bits and use predicate register to carry additional information between them (similar to x86 add and adc). Some of the opcodes are:
STG,LDG– store to and load from global memory.IMAD– integer multiply-add, computesdst := src0 * src1 + src2.ISETP[.CMP_OP][.LOGIC_OP]– integer set predicate. Sets the destination predicate register to the result of the comparison (CMP_OP) of the two given general-purpose registers merged, usingLOGIC_OPwith the value of the last source predicate register. There’s also.EXvariant used to handle the upper half of 64-bit value comparisons.BAR.SYNC– block barrier synchronisation. Synchronises all threads in a block.BSSY,BSYNC– convergence barrier. With the introduction of Independent Thread Scheduling in Volta microarchitecture, it is no longer guaranteed that all threads in a warp execute in lockstep. Convergence barriers provide a way for threads in a warp to converge after divergent execution.
That should be enough information to understand the code generated by the NVCC. One thing that stands out is the number of “auxiliary” instructions (computing memory addresses and comparisons) relative to the instructions that do the “real” work: memory loads, addition, and store. We will look into improving that situation later.
Let’s see how this code performs: 1
-------------------------------------------------------------------------
Benchmark Time CPU Iterations
-------------------------------------------------------------------------
sum_i32_array/33554432/real_time 1707 us 1705 us 410
sum_i32_array/67108864/real_time 3389 us 3385 us 205
sum_i32_array/268435456/real_time 13586 us 13572 us 51
sum_i32_array/536870912/real_time 27416 us 27387 us 25
sum_i32_array/536870912/real_time:
Calls Avg Min Max Name
360 27.893ms 27.560ms 35.361ms do_reduce
720 152.80us 3.0080us 347.85us do_reduce_blocks
Nsight Compute generally says that when executing do_reduce kernel the GPU is mostly busy not doing anything.
Section: GPU Speed Of Light
------------------------------------------------
Memory Frequency cycle/nsecond 1.70
SOL FB % 28.87
Elapsed Cycles 48,179,750.00
SM Frequency cycle/nsecond 1.41
Memory [%] % 28.87
Duration msecond 34.26
Waves Per SM 14,563.56
SOL L2 % 13.71
SOL TEX % 8.89
SM Active Cycles 45,551,767.42
SM [%] % 37.28
------------------------------------------------
Section: Memory Workload Analysis
------------------------------------------------
Memory Throughput Gbyte/second 125.39
Mem Busy % 13.71
Max Bandwidth % 28.87
L2 Hit Rate % 66.83
Mem Pipes Busy % 21.28
L1 Hit Rate % 60.37
------------------------------------------------
Section: Warp State Statistics
------------------------------------------------
Avg. Not Predicated Off Threads Per Warp 31.08
Avg. Active Threads Per Warp 31.79
Warp Cycles Per Executed Instruction 22.05
Warp Cycles Per Issued Instruction 22.05
Warp Cycles Per Issue Active 22.05
Stall Barrier inst 7.07
Stall Long Scoreboard inst 4.63
Stall Wait inst 2.85
...
Those results aren’t very surprising. GPUs rely on high concurrency to hide latencies, and reduce due to its very nature operation, starts with a considerable number of threads, but ends with very few doing useful work. The fact that we have a lot of global memory accesses and block-wide synchronisation barriers is not helping either. It is reflected in the warp state statistics section, which shows that two primary sources of stalls are barriers and “long scoreboard stalls”, i.e. L1TEX cache accesses.
If we look again at the main reduce loops, we see that every iteration halves the number of threads still doing useful work, but the others still need to keep executing many instructions. Those are wasted cycles, which, end up increasing the synchronisation barrier latency, since the “still-useful” warps need to wait for all the “useless” warps in a block. The easiest way to solve this problem is to exit threads early, as soon as there’s nothing else for them to do. Unfortunately, there appears to be some confusion as to whether this is allowed in the presence of __syncthreads(). The CUDA Programming Guide states that __syncthreads() waits for all threads in a block to reach the barrier, and horrors await those who let those threads diverge. The compatibility section says, however, that since Compute Capability 7.x (i.e. Volta and introduction of Independent Thread Scheduling) the __syncthreads() requirements are enforced more strictly and all non-exited threads must reach the barrier for it to succeed. In addition to that, the PTX documentation clearly states, that bar.sync an instruction to which __syncthreads() is usually (if not always) compiled takes only non-exited threads. In other words, according to the official specifications, it should be perfectly safe to use bar.sync with exited threads, but not necessarily __syncthreads(). I am going to keep using __syncthreads() in this article, though.
The second issue, excessive L1TEX stalls, is simpler to solve. Since we know precisely how our access pattern is going to look like, we can use shared memory and effectively manually manage cached data. If we assume the block size of 1024 threads and T being an integer, we can create a shared memory array and use it to store the intermediate values. The way we already have arranged threads and the values they are responsible ensures there won’t be any bank conflicts. Unfortunately, this won’t work if the size of T makes the array larger than the available shared memory or even big enough to reduce the occupancy on the Streaming Multiprocessor. In such case, the options are to either reduce the block size and either use dynamic shared memory or C++ template metaprogramming to decide on the size of the array or to stop using shared memory and rely on the cache entirely.
With the synchronisation and memory improvements, and assuming 1024-thread blocks and small T the kernel looks like this:
template<typename V, typename T, typename F>
__global__ auto do_reduce(size_t total_size, V in, T init, F fn, T* out) -> void {
auto id = blockIdx.x * blockDim.x + threadIdx.x;
if (id >= total_size) { return; }
auto tid = threadIdx.x;
__shared__ T tmp[1024];
tmp[tid] = in[id];
auto stride = blockDim.x / 2;
while (stride) {
__syncthreads(); // bar.sync
if (tid >= stride) { return; }
if (id + stride < total_size) { tmp[tid] = fn(tmp[tid], tmp[tid + stride]); }
stride /= 2;
}
if (id == 0) {
out[0] = fn(tmp[0], init);
} else if (tid == 0) {
out[id] = tmp[0];
}
}
Let’s see the numbers:
-------------------------------------------------------------------------
Benchmark Time CPU Iterations
-------------------------------------------------------------------------
sum_i32_array/33554432/real_time 1212 us 1211 us 575
sum_i32_array/67108864/real_time 2418 us 2415 us 290
sum_i32_array/268435456/real_time 9699 us 9689 us 70
sum_i32_array/536870912/real_time 19377 us 19357 us 35
sum_i32_array/536870912/real_time:
Calls Avg Min Max Name
451 20.376ms 20.064ms 26.792ms do_reduce
902 148.25us 3.0080us 339.02us do_reduce_blocks
That’s a nice improvement. Nsight Compute report shows us how things have changed:
Section: GPU Speed Of Light
------------------------------------------------
Memory Frequency cycle/nsecond 1.70
SOL FB % 20.63
Elapsed Cycles 34,099,309.00
SM Frequency cycle/nsecond 1.41
Memory [%] % 20.63
Duration msecond 24.20
Waves Per SM 14,563.56
SOL L2 % 10.92
SM Active Cycles 31,465,879.06
SM [%] % 17.61
------------------------------------------------
Section: Memory Workload Analysis
------------------------------------------------
Memory Throughput Gbyte/second 89.55
Mem Busy % 10.09
Max Bandwidth % 20.63
L2 Hit Rate % 0.78
Mem Pipes Busy % 17.61
L1 Hit Rate % 0
------------------------------------------------
Section: Memory Workload Analysis Chart
------------------------------------------------
dram__bytes_read.sum Gbyte 2.15
dram__bytes_write.sum Mbyte 19.32
Section: Warp State Statistics
------------------------------------------------
Avg. Active Threads Per Warp 30.31
Warp Cycles Per Executed Instruction 25.15
Stall Long Scoreboard inst 12.56
Stall Wait inst 4.51
Stall Barrier inst 2.93
...
The latency is still an issue, but now the main contributor to it are long scoreboard stalls, i.e. L1TEX operations. “Stall Wait” represents stalls caused by the stall cycle field in instructions control words and suggest insufficient instruction-level parallelism on the compute side of things. The memory throughput has dropped compared for the original kernel, but that’s okay since we are now not using global memory for intermediate values. That is confirmed by the dram__bytes_read.sum metric, as the kernel reads only 2GB of data which is exactly the size in bytes of the input range.
What that report essentially shows us is that we are bottlenecked on the memory latency without being nowhere near the maximum memory throughput. Since the input data is a contiguous array, and we know the memory locations that we need to read well ahead of time, our goal is to get as close to the maximum memory throughput as possible.
Let’s check the kernel SASS code annotated with the stall information.
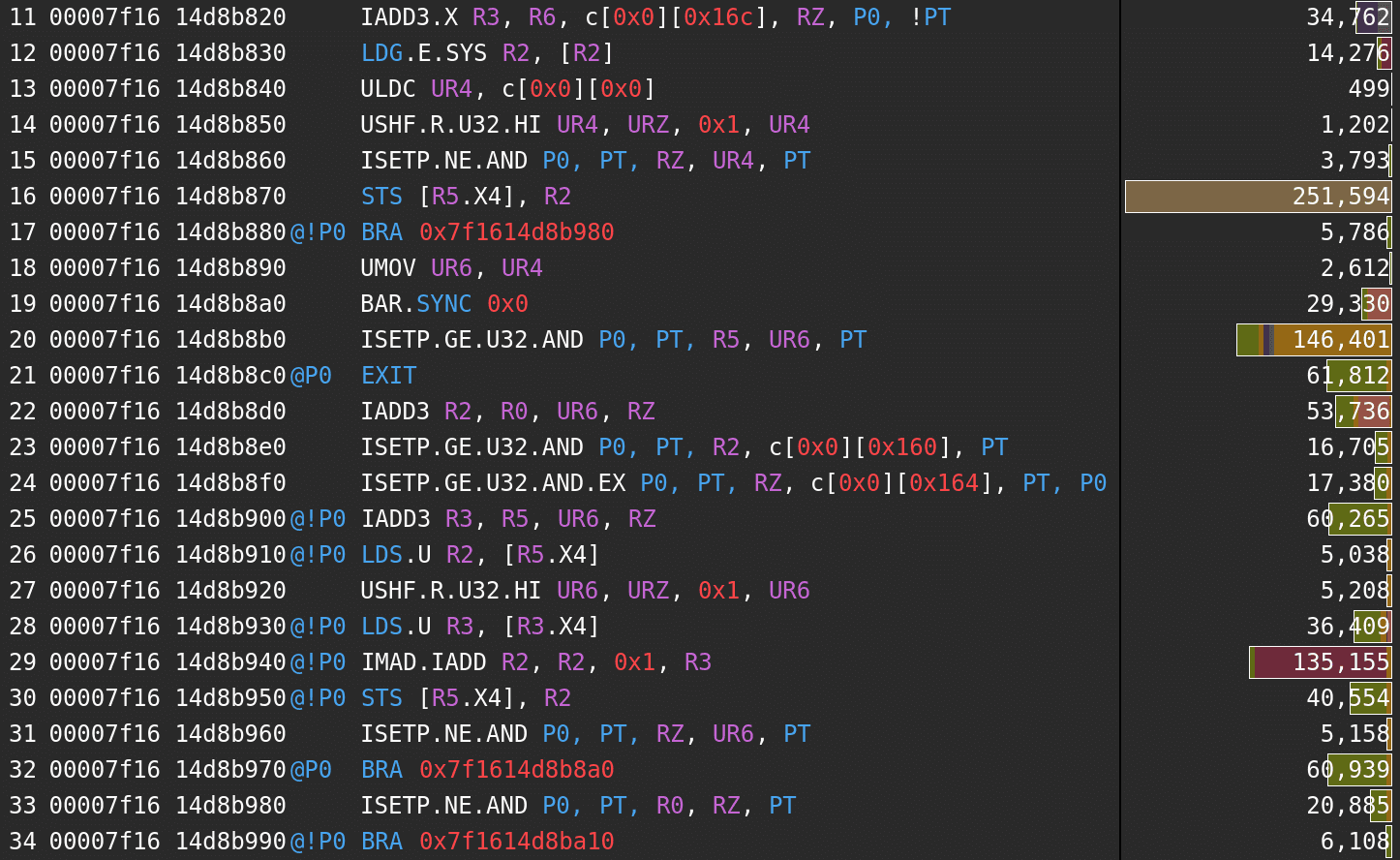
As the summary said, the main problem is a stall caused by global memory load: STS (shared memory store) instruction in line 16 is stalled, and its source register is the destination register of a global memory load in line 12.
What we can do is to read more, preferably, read more without adding more instructions so that we minimise cache hit latency. Fortunately, there’s LDG.E.128 instruction that reads 4 32-bit values. It’s not always trivial to convince NVCC to emit it but using int4 (or float4) types tends to do the trick. The thing worth to note here is that if each thread reads four values, it will need to merge them slightly reducing overall parallelism. That’s perfectly fine if the merge operation is something very cheap like an addition but may not be so for more expensive ones.
Since the reduce operation discussed here is a part of a ranges library that can handle pipelines with multiple transformation and filtering stage, we need a quite general way of allowing loading multiple values from memory at once. The load of N elements can be implemented as follows.
template<size_t N, typename T> struct vector { T elements[N]; };
template<size_t N, typename T> __device__ ::ranges_gpu::detail::vector<N, T> load(T const* ptr, unsigned idx) {
auto vec = ::ranges_gpu::detail::vector<N, T>{};
ptr += idx;
for (auto i = 0u; i < N; i++) { vec.elements[i] = ptr[i]; }
return vec;
}
template<> __device__ ::ranges_gpu::detail::vector<4, int> load<4, int>(int const* ptr, unsigned idx) {
auto val = *reinterpret_cast<int4 const*>(ptr + idx);
return {val.x, val.y, val.z, val.w};
}
Now, provided that all intermediate stages are adjusted to be able to work with multiple values, by adding a get_vector<N>() member function to them we can change our do_reduce kernel to the following implementation.
template<unsigned N, typename V, typename T, typename F>
__global__ auto do_reduce(size_t total_size, V in, T init, F fn, T* out) -> void {
auto id = blockIdx.x * blockDim.x + threadIdx.x;
auto tid = threadIdx.x;
if (id * N >= total_size) { return; }
__shared__ T tmp[1024];
if (id * N + N - 1 < total_size) {
auto v = in.get_vector<N>(id * N);
auto val = v.elements[0];
// FIXME: won't be able to parallelise this for floats
for (auto i = 1; i < N; i++) { val = fn(val, v.elements[i]); }
tmp[tid] = val;
} else {
/* slow path */
auto val = in[id * N];
for (auto i = 1; i < N && id * N + i < total_size; i++) {
val = fn(val, in[id * N + i]);
}
tmp[tid] = val;
}
auto stride = blockDim.x / 2;
while (stride) {
__syncthreads(); // bar.sync
if (tid >= stride) { return; }
if ((id + stride) * N < total_size) { tmp[tid] = fn(tmp[tid], tmp[tid + stride]); }
stride /= 2;
}
if (id == 0) {
out[0] = fn(tmp[0], init);
} else if (tid == 0) {
out[id * N] = tmp[0];
}
}
The main reducing loop remains mostly unchanged, but the kernel starts with reading N values and merging them. We can verify that NVCC, indeed, chooses to emit LDG.E.128 (with N=4).
0x00000270 --:-:2:Y:2 LDG.E.128.SYS R4, [R4]
0x00000280 04:-:-:-:5 IADD3 R6, R6, R5, R4
0x00000290 --:-:-:-:8 IMAD.IADD R6, R7, 0x1, R6
0x000002a0 --:0:-:Y:2 STS [R9], R6
An additional, minor, bonus here is that since we are now reducing four values instead of just two, the compiler can take advantage of IADD3 instruction that adds three integers, increasing compute throughput.
-------------------------------------------------------------------------
Benchmark Time CPU Iterations
-------------------------------------------------------------------------
sum_i32_array/33554432/real_time 389 us 389 us 1796
sum_i32_array/67108864/real_time 761 us 760 us 909
sum_i32_array/268435456/real_time 3009 us 3006 us 231
sum_i32_array/536870912/real_time 6076 us 6070 us 108
Calls Avg Min Max Name
1180 6.3046ms 6.2535ms 8.2248ms do_reduce
2360 34.098us 1.9200us 79.266us do_reduce_blocks
That’s a significant improvement. We have gone in the right direction. Let’s see how the memory situation looks like in the Nsight report.
Section: GPU Speed Of Light
------------------------------------------------
Memory Frequency cycle/nsecond 1.70
SOL FB % 65.90
Elapsed Cycles 10,589,798.00
SM Frequency cycle/nsecond 1.41
Memory [%] % 65.90
Duration msecond 7.53
Waves Per SM 3,640.89
SOL L2 % 20.72
SOL TEX % 18.79
SM Active Cycles 9,921,488.11
SM [%] % 16.17
------------------------------------------------
Section: Memory Workload Analysis
------------------------------------------------
Memory Throughput Gbyte/second 286.19
Mem Busy % 20.72
Max Bandwidth % 65.90
L2 Hit Rate % 0.20
Mem Pipes Busy % 14.17
L1 Hit Rate % 0
------------------------------------------------
Section: Memory Workload Analysis Chart
------------------------------------------------
dram__bytes_read.sum Gbyte 2.15
dram__bytes_write.sum Mbyte 6.67
Much better, but still not there. 66% of maximum throughput definitely can be improved. We can go further and read even more at the beginning of each thread. Let’s see what happens if we change the code to use two LDG.E.128 loads and merge eight values in the initial step.
// N = 8
auto idN = id * N;
auto v = in.get_vector<N / 2>(idN);
auto v2 = in.get_vector<N / 2>(idN + N / 2);
auto val = v.elements[0];
auto val2 = v2.elements[0];
// FIXME: won't be able to parallelise this for floats
for (auto i = 1; i < N / 2; i++) { val = fn(val, v.elements[i]); }
for (auto i = 1; i < N / 2; i++) { val2 = fn(val2, v2.elements[i]); }
tmp[tid] = fn(val, val2);
The improvement is much smaller than before but still noticeable.
-------------------------------------------------------------------------
Benchmark Time CPU Iterations
-------------------------------------------------------------------------
sum_i32_array/33554432/real_time 346 us 345 us 2023
sum_i32_array/67108864/real_time 674 us 674 us 1019
sum_i32_array/268435456/real_time 2661 us 2658 us 259
sum_i32_array/536870912/real_time 5352 us 5347 us 121
Calls Avg Min Max Name
1400 5.2248ms 5.2036ms 6.3349ms do_reduce
2800 22.134us 1.6960us 50.018us do_reduce_blocks
Nsight report says that we are at 92% of memory throughput. Since we are reading the input array exactly once, that’s it when it comes to what we can do. True, perhaps the input data could be compressed, or we could spend more time trying to figure out where the missing 8% went, but at this point, for a code which purpose is to take an input range and reduce it, it is undoubtedly well optimised.
Section: GPU Speed Of Light
------------------------------------------------
Memory Frequency cycle/nsecond 1.69
SOL FB % 92.96
Elapsed Cycles 7,510,548.00
SM Frequency cycle/nsecond 1.40
Memory [%] % 92.96
Duration msecond 5.35
Waves Per SM 1,820.44
SOL L2 % 29.16
SOL TEX % 26.09
SM Active Cycles 7,146,099.69
SM [%] % 12.17
------------------------------------------------
Section: Memory Workload Analysis
------------------------------------------------
Memory Throughput Gbyte/second 402.29
Mem Busy % 29.16
Max Bandwidth % 92.96
L2 Hit Rate % 0.10
Mem Pipes Busy % 11.54
L1 Hit Rate % 49.98
------------------------------------------------
Section: Memory Workload Analysis Chart
------------------------------------------------
dram__bytes_read.sum Gbyte 2.15
dram__bytes_write.sum Mbyte 4.66
While we’ve reached the device memory limits, that doesn’t mean there’s nothing left for us to play with. Let’s consider input ranges that are not read from memory but generated as we go.
void sum_i32_iota(benchmark::State& s) {
int bound = s.range(0);
for (auto _ : s) {
auto value = ranges_gpu::view::iota(0, bound)
| ranges_gpu::action::reduce(0,
[] __device__(auto a, auto b) { return a + b; },
ranges_gpu::pool_allocator<int>(pool));
benchmark::DoNotOptimize(value);
}
}
Our starting point, after all the optimisations we have done so far, is this:
-------------------------------------------------------------------------
Benchmark Time CPU Iterations
-------------------------------------------------------------------------
sum_i32_iota/33554432/real_time 145 us 144 us 3811
sum_i32_iota/67108864/real_time 265 us 265 us 2638
sum_i32_iota/268435456/real_time 1006 us 1004 us 696
sum_i32_iota/536870912/real_time 2025 us 2023 us 346
Calls Avg Min Max Name
4254 2.1628ms 2.1368ms 2.8474ms do_reduce
8508 26.552us 1.7280us 54.082us do_reduce_blocks
As expected, that’s faster than when the range was in memory but not as fast as it can get. Unsurprisingly, the latency is still the main problem, so let’s have a look at the annotated SASS.

The block synchronisation stall has made a comeback. There’s also a short scoreboard, i.e. shared memory latency stall and stalls forced by control information in multiple instructions. The good thing is that we can help with all of those issues.
- We don’t need the block synchronisation all the time. Once there’s only a single warp of active threads in a block we can switch to intra-warp synchronisation (e.g.
__syncwarp), which in case of non-divergent code can end up being a no-op. - We don’t need to load two values from shared memory at each step since one of them is the output of the previous step. Moreover, once we have only a single warp, we can use warp lane shuffles to transfer values between threads.
- There’s a lot of control logic and the loop is not unrolled. Most of that is to handle the special case of the lack block which may not be full. We should check for that early and have a fast path that assumes a certain block size and that all values are present.
if (blockDim.x == 1024 && (blockIdx.x + 1) * blockDim.x * N <= total_size) {
auto v = in.get_vector<N / 2>(id * N);
auto v2 = in.get_vector<N / 2>(id * N + N / 2);
auto val = v.elements[0];
auto val2 = v2.elements[0];
// FIXME: won't be able to parallelise this for floats
for (auto i = 1; i < N / 2; i++) { val = fn(val, v.elements[i]); }
for (auto i = 1; i < N / 2; i++) { val2 = fn(val2, v2.elements[i]); }
val = fn(val, val2);
tmp[tid] = val;
auto stride = 512;
while (stride >= 32) {
__syncthreads(); // bar.sync
if (tid >= stride) { return; }
val = fn(val, tmp[tid + stride]);
stride /= 2;
tmp[tid] = val;
}
__syncthreads();
while (stride) {
val2 = __shfl_down_sync(FULL_MASK, val, stride);
val = fn(val, val2);
stride /= 2;
}
if (tid == 0) { tmp[0] = val; }
} else {
/* slow block */
}
The performance improvement is quite significant.
-------------------------------------------------------------------------
Benchmark Time CPU Iterations
-------------------------------------------------------------------------
sum_i32_iota/33554432/real_time 89 us 89 us 6170
sum_i32_iota/67108864/real_time 160 us 160 us 4378
sum_i32_iota/268435456/real_time 603 us 602 us 1162
sum_i32_iota/536870912/real_time 1222 us 1220 us 573
Calls Avg Min Max Name
6025 1.3572ms 1.3409ms 1.7726ms do_reduce
12050 26.574us 1.7280us 54.017us do_reduce_blocks
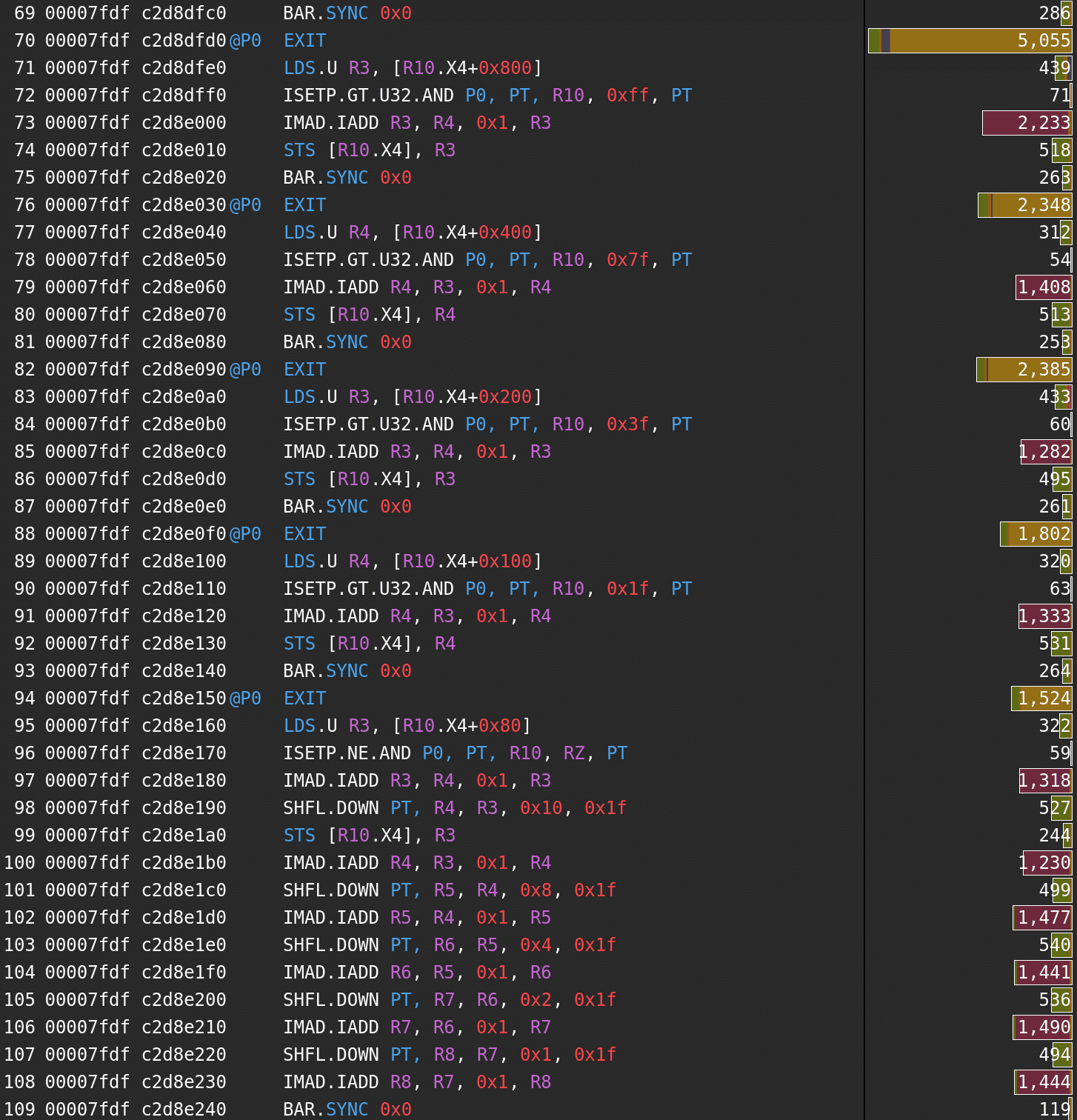
Both loops are now nicely unrolled, but the latency is still a problem. Two main contributors are fixed-latency instructions and block synchronisation. We can also see that the latency of lane shuffle, even if not the most significant issue at the moment, is likely to cause trouble soon.
Section: GPU Speed Of Light
------------------------------------------------
Memory Frequency cycle/nsecond 1.69
SOL FB % 0.38
Elapsed Cycles 2,138,690.00
SM Frequency cycle/nsecond 1.41
Memory [%] % 12.95
Duration msecond 1.52
Waves Per SM 1,820.44
SOL L2 % 0.20
SOL TEX % 15.29
SM Active Cycles c1,810,219.44
SM [%] % 27.69
------------------------------------------------
Section: Warp State Statistics
------------------------------------------------
Avg. Active Threads Per Warp 31.86
Warp Cycles Per Executed Instruction 12.84
Stall Wait inst 3.30
Stall Barrier inst 2.58
Stall Not Selected inst 2.07
...
The synchronisation barrier latency penalty can be dealt with by reducing the number of __syncthreads() calls by reducing four, instead of two values per each iteration of the loop. It also turns out that we can squeeze some more performance by rearranging the C++ code in a way that would make NVCC generate better code. That includes simplifying the condition check for the slow path and making sure that fast path doesn’t require a branch, not sharing the exit code so that it can be optimised more heavily, exiting threads before a call to __syncthreads().
template<unsigned N, typename V, typename T, typename F>
__global__ auto do_reduce(size_t total_size, V in, T init, F fn, T* out) -> void {
auto tid = threadIdx.x;
__shared__ T tmp[1024];
if (!(blockDim.x == 1024 && (blockIdx.x + 1) * 1024 * N <= total_size)) {
/* slow path */
return;
}
auto id = blockIdx.x * 1024 + threadIdx.x;
auto v = in.get_vector<N / 2>(id * N);
auto v2 = in.get_vector<N / 2>(id * N + N / 2);
auto val = v.elements[0];
auto val2 = v2.elements[0];
// FIXME: floats won't be able to parallelise this
for (auto i = 1; i < N / 2; i++) { val = fn(val, v.elements[i]); }
for (auto i = 1; i < N / 2; i++) { val2 = fn(val2, v2.elements[i]); }
val = fn(val, val2);
auto stride = 256;
while (stride >= 16) {
tmp[tid] = val;
if (tid >= stride) { return; }
__syncthreads(); // bar.sync
val = fn(fn(val, tmp[tid + stride]), fn(tmp[tid + stride * 2], tmp[tid + stride * 3]));
stride /= 4;
}
if (tid >= 16) { return; }
stride *= 2;
while (stride) {
val2 = __shfl_down_sync(0xffff, val, stride);
val = fn(val, val2);
stride /= 2;
}
if (tid != 0) { return; }
if (id == 0) {
val = fn(val, init);
}
out[id * N] = val;
}
-------------------------------------------------------------------------
Benchmark Time CPU Iterations
-------------------------------------------------------------------------
sum_i32_iota/33554432/real_time 73 us 73 us 7393
sum_i32_iota/67108864/real_time 127 us 127 us 5513
sum_i32_iota/268435456/real_time 471 us 471 us 1485
sum_i32_iota/536870912/real_time 960 us 958 us 729
That’s better, but we are not done yet. As we’ve seen earlier, the lane shuffle latency is big enough to show up in the profile. The reason for that is that the latency of SHFL.DOWN appears to be 23 cycles and the warp-level reduce part of the code is just a chain of dependent shuffles and addition with no parallelism whatsoever. We could try to improve this code ourselves (more concurrent shuffles and additions seems like a good place to start), but let’s make things more interesting and use a superoptimiser for this.
0x000002f0 01:-:0:Y:2 SHFL.DOWN PT, R4, R3, 0x8, 0x1f
0x00000300 01:-:-:-:8 IMAD.IADD R4, R3, 0x1, R4
0x00000310 --:-:0:Y:2 SHFL.DOWN PT, R5, R4, 0x4, 0x1f
0x00000320 01:-:-:-:8 IMAD.IADD R5, R4, 0x1, R5
0x00000330 --:-:0:Y:2 SHFL.DOWN PT, R6, R5, 0x2, 0x1f
0x00000340 01:-:-:-:8 IMAD.IADD R6, R5, 0x1, R6
0x00000350 --:0:1:Y:1 SHFL.DOWN PT, R7, R6, 0x1, 0x1f
A superoptimizer is a tool that, given a piece of code, attempts to find an optimal equivalent program. I’ve been playing around with my toy superoptimiser, which uses a stochastic approach. The general idea is that it mutates the current candidate program and then assigns it a score based on the correctness and the performance. If the score of the new candidate is better than the current one, it is always accepted. If the score is worse, the new candidate is randomly accepted with a probability depending on how much worse the new score is. This ensures that the superoptimizer has a chance of exploring any code sequence while preferring the well-scored ones.
The mutations applied to the programs are as follows:
- change opcode of a random instruction
- change random operand in a random instruction
- insert a new random instruction
- remove a random instruction
- swap two random instructions
The superoptimiser works directly with the machine-code (in this case Turing ISA).
Correctness score is computed by executing a series of tests and adding a penalty for each test that the candidate returns a different value than the original program. That’s not enough to prove equivalence, though. If a candidate passes all tests and has a total score better than any program the superoptimiser has seen so far it asks an SMT solver (Z3 in this case) whether there exists a set of inputs for which the candidate and the original program return different values. If the answer is no, then the candidate is correct. If there is at least one such set, then it is added as a new test case, and the candidate score is reevaluated.
Performance is scored by estimating the latency of the code sequence so far a very simplified model is used that assumes single-dispatch in-order architecture, has no consideration on throughput limitations and no concepts of register bank conflicts. Those restrictions are not going to be a serious problem in this case, though.
Given the warp-level reduce code shown earlier the superoptimiser, after some time, outputs the following code sequence:
SHFL.DOWN r4, r3, 8
SHFL.DOWN r0, r3, 12
SHFL.DOWN r7, r3, 4
IADD3 r2, r255, r4, r3
IADD3 r5, r0, r7, r2
SHFL.DOWN r7, r5, 3
SHFL.DOWN r1, r5, 2
SHFL.DOWN r9, r5, 1
IADD3 r7, r5, r255, r7
IADD3 r7, r1, r7, r9
Well, we probably didn’t need to implement a superoptimiser to figure out that doing more concurrent shuffles and additions may help with latency, but it’s good to see that it can find such optimised code and agrees with our intuition. In C++ that snippet is going to look more or less like this:
auto v2 = __shfl_down_sync(0xffff'ffff, val, 8);
auto v3 = __shfl_down_sync(0xffff'ffff, val, 12);
auto v4 = __shfl_down_sync(0xffff'ffff, val, 4);
auto v5 = fn(fn(v2, val), fn(v3, v4));
v2 = __shfl_down_sync(0xffff'ffff, v5, 3);
v3 = __shfl_down_sync(0xffff'ffff, v5, 2);
v4 = __shfl_down_sync(0xffff'ffff, v5, 1);
val = fn(fn(v2, v3), fn(v5, v4));
This superoptimisation was, indeed, an optimisation:
-------------------------------------------------------------------------
Benchmark Time CPU Iterations
-------------------------------------------------------------------------
sum_i32_iota/33554432/real_time 72 us 72 us 8098
sum_i32_iota/67108864/real_time 127 us 126 us 5768
sum_i32_iota/268435456/real_time 447 us 446 us 1566
sum_i32_iota/536870912/real_time 917 us 916 us 763
It would be great if we could give the superoptimiser the whole kernel and get its optimal version in a reasonable amount of time, but that’s sadly not the case. The fact that the ISA and performance characteristics need to be reverse-engineered only makes things more difficult.
We are reaching the limits of how much a general reduce algorithm can be optimised. There are still some things that are worth trying. In particular, we can adjust ratios between block synchronisation barriers and lane shuffles and reduce operations. The cheaper reduce (and addition is very cheap) the more values can be processed in each step. As it turns out, I get the best results when there’s just a single warp per block, reducing elements of the range in steps of 32, 8, and 4:
tmp[tid] = val;
if (tid >= 32) { return; }
auto stride = 32;
__syncthreads();
T vals[32] = { };
for (auto i = 1; i < 32; i++) {
vals[i] = tmp[tid + stride * i];
}
for (auto i = 1; i < 32; i++) {
val = fn(val, vals[i]);
}
if (tid >= 32) { return; }
for (auto i = 1; i < 8; ++i) {
vals[i] = __shfl_down_sync(0xffff'ffff, val, i*4);
}
for (auto i = 1; i < 8; ++i) {
val = fn(val, vals[i]);
}
for (auto i = 1; i < 4; ++i) {
vals[i] = __shfl_down_sync(0xffff'ffff, val, i);
}
for (auto i = 1; i < 4; ++i) {
val = fn(val, vals[i]);
}
That code gives us:
-------------------------------------------------------------------------
Benchmark Time CPU Iterations
-------------------------------------------------------------------------
sum_i32_iota/33554432/real_time 66 us 65 us 8071
sum_i32_iota/67108864/real_time 111 us 111 us 6316
sum_i32_iota/268435456/real_time 414 us 413 us 1690
sum_i32_iota/536870912/real_time 843 us 841 us 831
Conclusion
We have dealt with memory throughput, instruction latency, intra-block and intra-warp thread synchronisation. A lot of what we have done made sense only for the particular code that was optimised and won’t work well in general cases, but there are some patterns. The size of the values and the cost of binary operation can make a significant impact. Moreover, the fact that GPUs rely on high concurrency to hide latency is making things more complicated (or interesting, or both) in case of operations like reduce. A generic implementation needs to navigate all those problems and decide between ease of use, the flexibility it provides, and how performant it can be compared to a custom solution.
One thing is sure. We won’t be seeing superoptimising complete programs anytime soon.
Related links
- Dissecting the NVIDIA Volta GPU Architecture via Microbenchmarking
- Dissecting the NVidia Turing T4 GPU via Microbenchmarking
- Tuning CUDA Applications for Turing
- Parallel Thread Execution ISA Version 6.4
- Program Synthesis Explained
- Program Synthesis
- STOKE: A stochastic superoptimizer and program synthesizer
NVIDIA GeForce RTX 2070 ↩︎